
前回の
utilitiesのmysqlfailoverを使う(1)で設定・起動は完了しています。
私の目的は2台のMySQLサーバーを定期的に入れ替えてメンテナンスすることです。
今回はマスターがダウンした時、自動でスレーブがマスターになるか。
マスターだったものがスレーブとして再度復帰できるか。
新しくスレーブを追加する場合はどうすればいいのかを解説です。
Windows8:192.168.0.99。mysqlfailoverを起動する
└centos:マスター。192.168.0.100。Windows8上のvmwareで起動
└centos:スレーブ。192.168.0.101。Windows8上のvmwareで起動
MySQLのバージョンは5.6.13。
MySQL Utilities mysqlfailover version 1.2.0 – MySQL Workbench Distribution 5.2.47
【目的】
通常はマスターを使用する。メンテナンス等でマスターとスレーブを切り替えたい。
その場合はスレーブをそのままマスターとし、スレーブはマスターとなる。
要するに自由に切り替えたい。
自動ファイルオーバー
mysqlfailoverの役割は、マスターがダウンした場合に自動でスレーブをマスターにすることです。
これは非常に簡単です・・・というかmysqlfailoverが自動でやってくれます。
下はmysqlfailoverを起動した状態の画面です。
この状態でマスターである100のMySQLをstopします。
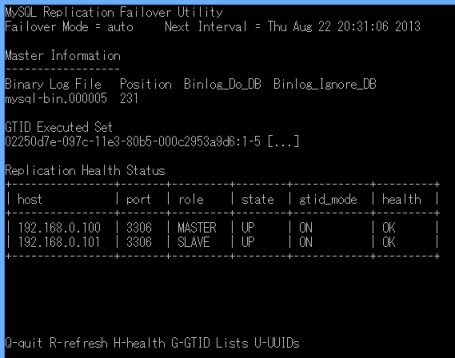
すると自動でなやらチェックしはじめます。
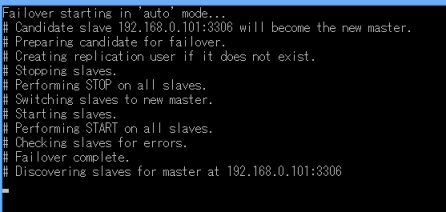
数秒後には自動でスレーブだった101がマスターに昇格していることが確認できます。

マスターだった100をスレーブにして接続する
マスターだったサーバーのメンテナンス?等も無事に終わったとします。
今度はマスターだったサーバーをスレーブとして参加させたいと思います。
スレーブだった端末はmysqlfailoverで自動的にマスターとなっています。
ですからマスターだった端末にスレーブの設定をするだけです。
//スレーブの停止(これは不要ですがやっても問題ないセットで覚えるべき?)
mysql> stop slave;
Query OK, 0 rows affected (0.04 sec)
//マスターのリセット
mysql> reset master;
Query OK, 0 rows affected (0.01 sec)
//マスターの再設定
mysql> change master to
-> master_host='192.168.0.101',
-> master_port=3306,
-> master_user='repl',
-> master_password='pass',
-> master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.02 sec)
//スレーブの開始
mysql> start slave;
Query OK, 0 rows affected (0.06 sec)
以上で完了です。
簡単だったでしょう!
切り戻しの際の注意(1)
マスターをスレーブとして再度参加させることは簡単です。
しかしmysqlfailoverでは、マスターの候補に現在マスターである端末は設定できません。
要するに次回新マスターである101(旧スレーブ)を停止しても、今度は自動的にスレーブがマスターにはなりません。
一度mysqlfailoverを停止して、パラメーターを変更して再起動しておく必要がります。
切り戻しの際の注意(2)
いままでの手順で問題なく切り戻しも完了できていることでしょう。
しかし、再度mysqlfailoverを起動した段階で、スレーブのhelthcheckに必ず問題が起こります。
MySQL Replication Failover Utility Failover Mode = auto Next Interval = Fri Aug 23 01:54:54 2013 Master Information ------------------ Binary Log File Position Binlog_Do_DB Binlog_Ignore_DB mysql-bin.000001 994 GTID Executed Set 02250d7e-097c-11e3-80b5-000c2953a9d6:1-2 [...] Replication Health Status +----------------+-------+---------+--------+------------+----------------------------------------------------------------------+ | host | port | role | state | gtid_mode | health | +----------------+-------+---------+--------+------------+----------------------------------------------------------------------+ | 192.168.0.101 | 3306 | MASTER | UP | ON | OK | | 192.168.0.100 | 3306 | SLAVE | UP | ON | SQL thread is not running., Slave has 2 transactions behind master. | +----------------+-------+---------+--------+------------+----------------------------------------------------------------------+
必ずSQL thread is not running., Slave has X transactions behind master.となってしまうのです。
この原因がなかなかわからずかなりはまりました・・・
各サーバーでSELECT @@GLOBAL.GTID_EXECUTED;を発行しましょう。
(もしくはshow slave status\Gでもかまいません。)
新しいマスター側 mysql> SELECT @@GLOBAL.GTID_EXECUTED; +----------------------------------------------------------------------------------+ | @@GLOBAL.GTID_EXECUTED | +----------------------------------------------------------------------------------+ | 02250d7e-097c-11e3-80b5-000c2953a9d6:1-2, b5c7a552-08b9-11e3-bbc1-000c2973a9ab:1 | +----------------------------------------------------------------------------------+ 1 row in set (0.00 sec) これは02250d7e・・・の1から2までとb5c7a552・・・の1を実行したということ。 新しいスレーブ側 mysql> SELECT @@GLOBAL.GTID_EXECUTED; +----------------------------------------+ | @@GLOBAL.GTID_EXECUTED | +----------------------------------------+ | 02250d7e-097c-11e3-80b5-000c2953a9d6:1 | +----------------------------------------+ 1 row in set (0.00 sec) これは02250d7e・・・の1を実行したということ。 結局02250d7e・・・の2とb5c7a552・・・の1がまだ実行できていないことになる。
上記のように実行したトランザクションにずれがでているのです。
マスター側にしかない
02250d7e-097c-11e3-80b5-000c2953a9d6:1-2,
というトランザクションは、以前スレーブだった時にマスター側から受け取って実行したトランザクションのGTIDです。
マスターとスレーブを入れ替えればそれだけ
Slave has X transactions behind master.
が増えて行ってしまいます。
気持ちわるいので綺麗にするためには、
新しいマスター側でもreset master をする必要がります。
そうするとスレーブ側でも再度masterの設定が必要になります。
しかし、マスター側でのreset maserは何も停止することなくできるので、大きな問題はないでしょう。
//新マスター側(101) mysql> reset master; Query OK, 0 rows affected (0.03 sec)
マスターでreset masterをするとスレーブはとまってしまいます。
がスレーブでやる手順はいつも同じです。
//新スレーブ側(100)
mysql> stop slave;
Query OK, 0 rows affected (0.02 sec)
mysql> reset master;
Query OK, 0 rows affected (0.01 sec)
mysql> change master to
-> master_host='192.168.0.101',
-> master_port=3306,
-> master_user='repl',
-> master_password='pass',
-> master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> start slave;p
Query OK, 0 rows affected (0.02 sec)
この後mysqlfailoverを確認してみてください。
Replication Health Status +----------------+-------+---------+--------+------------+---------+ | host | port | role | state | gtid_mode | health | +----------------+-------+---------+--------+------------+---------+ | 192.168.0.101 | 3306 | MASTER | UP | ON | OK | | 192.168.0.100 | 3306 | SLAVE | UP | ON | OK | +----------------+-------+---------+--------+------------+---------+
切り戻しまとめ
だらだら書きましたが結局は
//1.新しいマスターで
mysql> reset master;
//2.新しいスレーブで
mysql> stop slave;
Query OK, 0 rows affected (0.01 sec)
mysql> reset master;
Query OK, 0 rows affected (0.03 sec)
mysql> change master to
-> master_host='192.168.0.100',
-> master_port=3306,
-> master_user='repl',
-> master_password='pass',
-> master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.06 sec)
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)
//3.mysqlfailoverを再起動しておく
ということです。

